

Case Study: How an Enterprise Tech Team Went from Dozens to 2,000+ Fine-Tuning Configurations
Written By:
Arun Kumar
Published on
The Use Case
An AI-forward team at a Fortune 500 enterprise tech company builds intelligent autocomplete for enterprise form data entry: predicting what a user will select next across product dimensions, pricing fields, and feature options. As part of their R&D, they were exploring a small language model (a TabTransformer) trained via Supervised Fine-Tuning (SFT) on tabular customer data. Running an SLM locally avoids sending sensitive customer data to external model APIs.
With their training dataset of 20,000 examples, categorical predictions were already strong. The hard problem was predicting numerical columns; validation accuracy varied dramatically with dataset quality and distribution skew. Getting this right meant exploring a large configuration space for fine-tuning the model to boost accuracy: not just hyperparameters (e.g., learning rate, batch size, attention heads, etc.), but also training strategies such as column masking.
What Was Slowing Them Down
The team ran experiments from Jupyter notebooks on a GCP Vertex AI instance with 4 Tesla T4 GPUs. Execution was sequential: each configuration had to finish training across the full dataset before the next could start. So, they could only run only a few dozen configurations without incurring higher resource costs, or the full sweeps took 5-6 days. The team would then eyeball MLflow dashboards, pick 3-4 promising configs, and extend those for 20 more epochs. Notebooks sometimes crashed from disk pressure of checkpoints. GPUs sat idle between runs. Most of the design space never got explored.
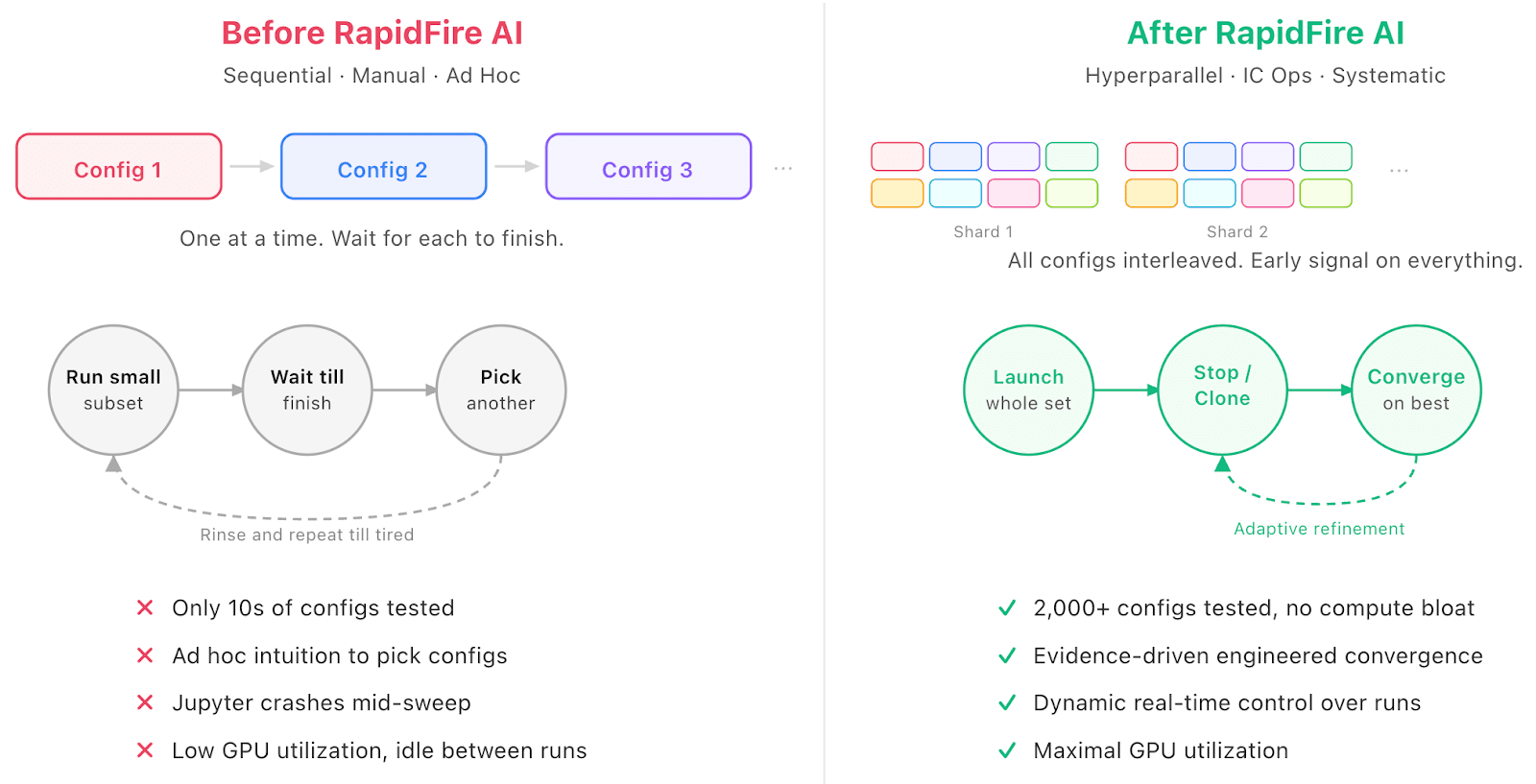
Figure 1. The SFT use case experimentation workflow before and after RapidFire AI. Sequential execution and manual trial-and-error gave way to shard-based hyperparallel comparisons with dynamic control, enabling 2,000+ structured configurations on the same hardware.
How RapidFire AI Changes the Game
Traditional tools force sequential execution: each config sees the full dataset before the next starts. RapidFire AI’s industry-first adaptive execution engine takes a fundamentally different approach: it shards the dataset and schedules all configurations one shard at a time, cycling through shards. You can see the learning behavior and metrics of all configurations after just the first shard or two, not after days of waiting.
On the 4-GPU instance, this meant comparing dozens of configurations in near real-time where they previously could see only one at a time. (For a deeper look at RapidFire AI’s innovative shard-based scheduling, adapter swapping, and shared memory management, see: What Makes RapidFire AI Different?)
While that is already a multiplier, a big level up comes from what happens next.
Real-Time Control Over Runs in Flight
Shard-based execution unlocks something sequential tools cannot offer: decisions about runs while they are still running. RapidFire AI calls these Interactive Control Operations (IC Ops).
After just a few shards, the team could stop underperformers (freeing GPU resources immediately), clone a promising config with a modified knob or two, and warm-start the clone from the parent’s learned parameters. This creates a compounding effect: where sequential execution compares N configs in N time units, IC Ops lets you explore a much larger effective space in the same wall-clock budget. Such decisions can also be done from the code itself to programmatically specify the logic for what to stop. This enabled the team to control the mass of runs in a fine-grained manner.
For this enterprise tech company, this compounding across 4 GPUs enabled the leap from dozens of manually managed runs to 2,000+ structured configurations, without bloating compute spend.
Engineered Convergence Driven by Evidence
Up until now, “convergence” in AI often meant trying a handful of configs to completion and picking winners via post-hoc checks. Now with RapidFire AI, every configuration’s trajectory is visible side-by-side from the first shard. Decisions to stop, continue, or branch can be grounded in comparative metrics, not ad hoc intuition. Everything is tracked in its MLflow-fork dashboard: configs, IC Op decisions, metrics, and logs. When final configs get chosen for production, the provenance chain is fully available for tracking and governance.
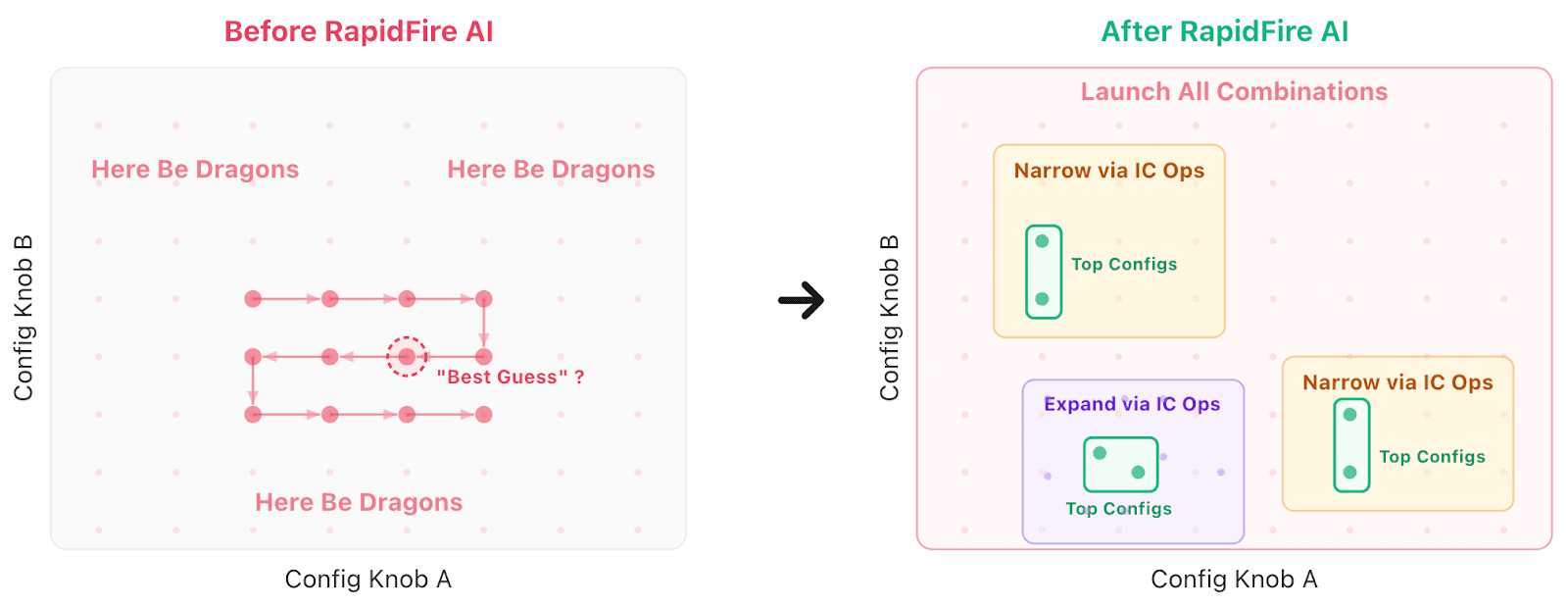
Figure 2. Same configuration space, paradigm shift of RapidFire AI. Before, only a few configs are explored, with most of the landscape ignored. After RapidFire AI, hyperparallelism enables exploring orders of magnitude more configs, while IC Ops enables narrowing to promising subsets and also expanding to new promising subsets based on results, leading to more top configs. This is not just faster search–it is engineered convergence.
The Takeaway
When asked for a time/impact comparison, the team gave a telling answer: It is not apples to apples because we were not able to try these many configurations before without RapidFire AI. Instead, it is a qualitative leap from “how many configs can we afford to try” to “how fast can we explore to converge to better metrics.”
The team is already looking ahead to applying RapidFire AI to other tabular + text use cases such as synthetic data augmentation on over 100-column datasets with variational autoencoders. RapidFire AI’s upcoming distributed execution and promptable agentic automation will drive even faster convergence and better metrics without manual grunt work.
For any team doing SFT, be it on tabular or multimodal data, on LLMs or domain-specific DL architectures, the takeaway is the same: RapidFire AI turns configuration experimentation from a sequential bottleneck into an engineered convergence process to boost your AI impact without bloating your resource spend.
RapidFire AI works beyond SFT. It applies equally to (multi-)agentic workflows and RAG/GraphRAG use cases too, whether on closed model APIs (e.g., OpenAI) or self-hosted open LLMs, and to post-training methods like DPO or GRPO. You get the same benefits: testing far more configurations quickly and converging to the best result systematically. Check out the resources below for more information.
Ready to try it?
