
Solutions
Cybersecurity
This example shows how to fine-tune a small instruction-tuned model to produce technically accurate cybersecurity answers—then use a structured 2×2 experiment grid to find the best trade-off between adaptation depth and learning aggressiveness.





Agent
A fine-tuned causal LLM trained via SFT + LoRA (PEFT) on Qwen2.5-1.5B-Instruct, with experiments across LoRA target module coverage and learning rate schedule.
Objectives
This example can serve as a starting point to understand how to rapidly experiment to:
Shift the model's posterior toward specialized cybersecurity vocabulary even when questions are asked in layman's language.
Improve answer quality on technical QA without overfitting to a small dataset or destroying general capabilities.
Key takeaways
Heavy adaptation is the biggest lever: Targeting all linear layers (not just Q/V projectors) was the most impactful knob—Run 2 (heavy + aggressive) achieved the highest BERTScore (0.8347) and ROUGE-L (0.2715), well ahead of the baseline (0.7984 / 0.1839).
Both knobs are monotonic: Aggressive learning always beats stable learning, and heavy adaptation always beats light adaptation. This suggests the model still had room to absorb more domain signals.
Beware of catastrophic forgetting: The most aggressive config carries the highest risk of losing general-purpose capabilities. Evaluating on a general benchmark (e.g., MMLU) would reveal how much baseline knowledge was sacrificed.
Measure + sanity-check: With only 50 eval rows, treat metric differences as directional and validate with human review of sample outputs.

Comparison of training and evaluation loss curves for cybersecurity SFT experiments.
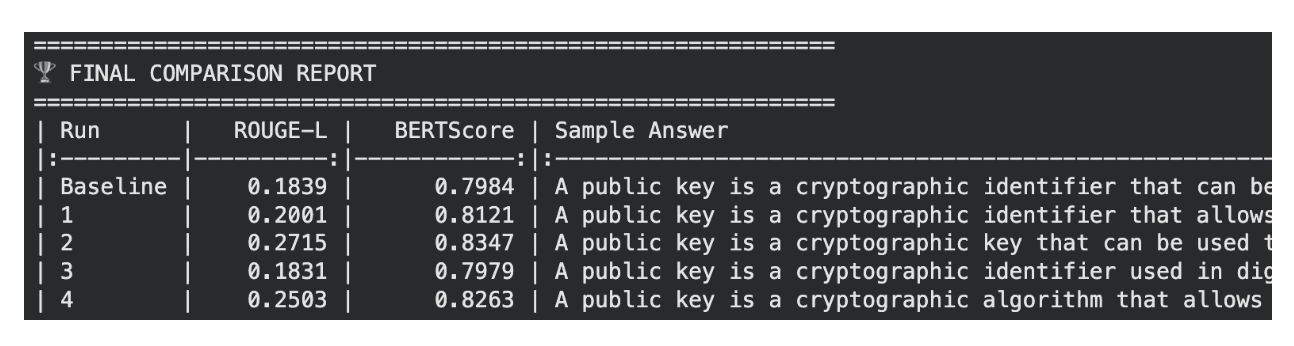
Performance comparison of SFT experiments for cybersecurity domain adaptation, showing BERTScore and ROUGE-L improvements across different LoRA target module configurations and learning rate schedules.

How to apply this to your domain
Use this workflow as a template for your own chatbot:
Pick a domain dataset where the target vocabulary distribution differs meaningfully from general pretraining.
Start with a lightweight instruction-tuned base and sweep a small grid: LoRA target modules, learning rate schedule, and optionally LoRA rank.
Pick winners using held-out eval + human review for helpfulness, policy adherence, tone, and refusal behavior (don’t rely on one metric alone in small-data regimes). Fine-Tuning-Design-Summary - La…

