
Solutions
Retail Chatbot
Retail chatbots must handle the full spectrum of e-commerce customer interactions—from product discovery and sizing guidance to order tracking, returns, and promotional questions.




This example shows how to fine-tune a small open-source chat model to respond to retail/e-commerce customer questions more consistently and in a fixed support style—then use outcome-driven experimentation to converge on the best configuration.

Dataset
bitext/Bitext-retail-ecommerce-llm-chatbot-training-dataset
Agent
A fine-tuned causal LLM used as a retail support chatbot, trained via SFT + LoRA (PEFT), with experiments across prompt format and LoRA capacity/coverage.
Objectives
This example can serve as a starting point to understand how to rapidly experiment to:
Keeps responses on-brand and on-format (consistent support voice and structure).
Improves answer quality on common retail workflows like orders, shipping, returns, and product questions, without relying on copying canned text.
Key takeaways
Capacity matters
Giving the model enough adaptation “room” (LoRA rank + module coverage) was the biggest driver of improvement.
Format helps when it’s trained enough:
Prompt/format changes alone weren’t a guaranteed win in tiny-data settings.
Measure + sanity-check:
With very small eval sets, treat results as directional and validate with quick human checks for tone, correctness, and format consistency.
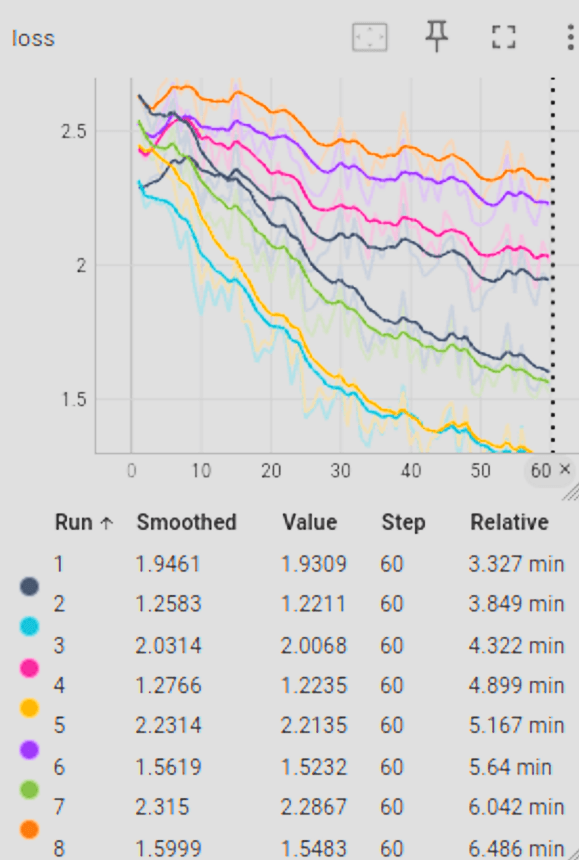
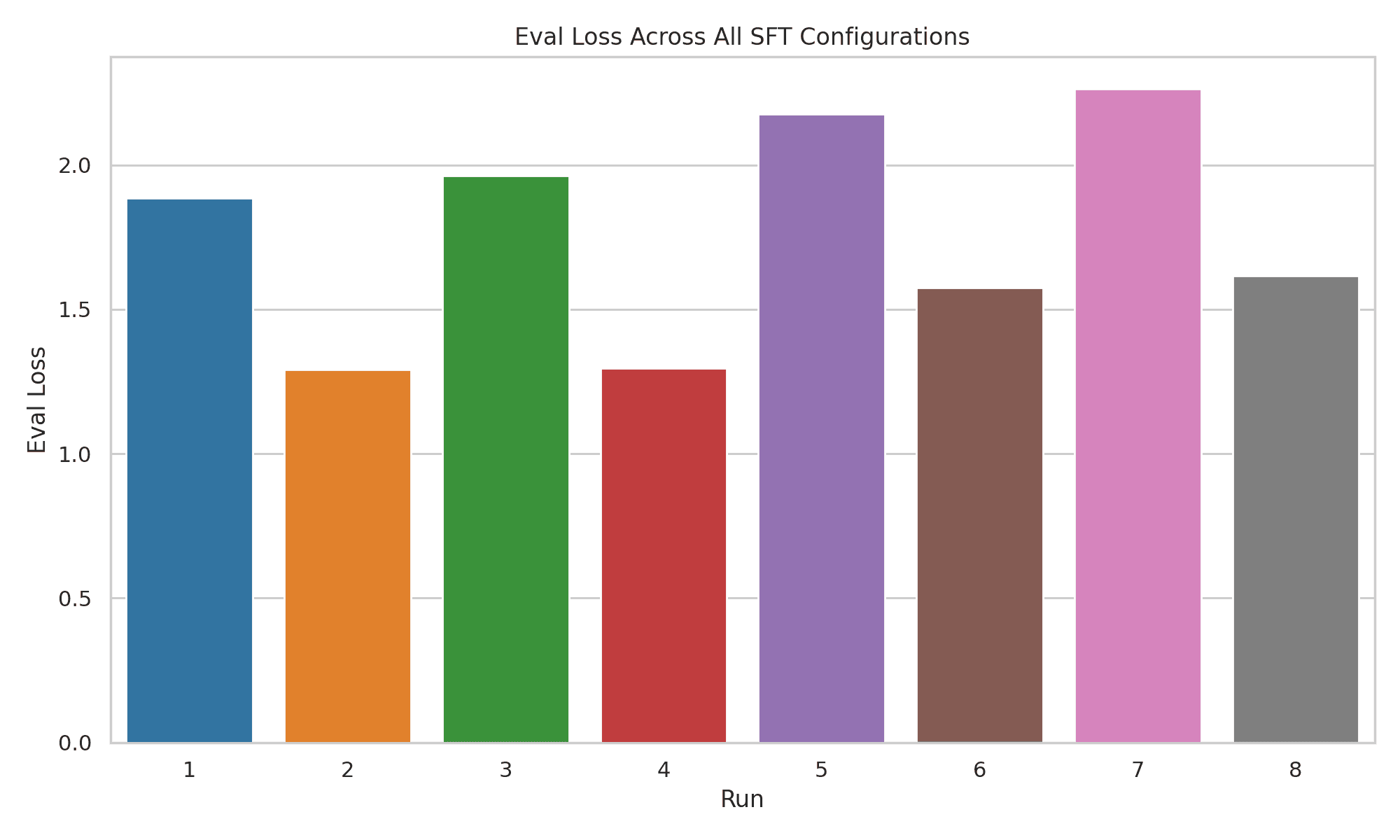
Comparison of SFT experimental runs for retail chatbot optimization, highlighting Run 3 as the configuration with the highest performance metrics


How to apply this to your support data
Use this workflow as a template for your own chatbot:
Turn your tickets/macros/KB articles into instruction-following pairs (question → best support answer).
Start with a lightweight base model and sweep a small set of knobs: format, LoRA capacity, target modules, base model size.
Pick winners using held-out eval + human review for helpfulness, policy adherence, tone, and refusal behavior (don’t rely on one metric alone in small-data regimes). Fine-Tuning-Design-Summary - La…

